From The Field: The First Annual Canonical Model Management Forum
Early last week, I attended the first annual “Canonical Model Management Forum” here in the DC area. A number of government agencies as well as several of the major banks, insurance companies, credit-card operators, and other private-sector firms attended the meeting. There was one vendor sponsor (DigitalML, the vendor of IgniteXML), and the meeting was hosted at a CSC facility. There were a number of presentations by the attendees about their environments, what had motivated them to establish a canonical model, how that work had turned out, and the important lessons learned.
But What Is A Canonical Information Model?
In the first day of sessions, I heard a number of definitions of canonical modeling, but most were similar to Forrester’s:
A canonical information model is a model of the semantics and structure of information that adheres to a set of rules agreed upon within a defined context for communicating among a set of applications or parties.
Forrester’s recent survey data shows that canonical modeling is actually quite common among those pursuing SOA:

OK – But Why Do I Need One?
But why were the agencies and private-sector companies at this meeting so concerned about how to manage their model? They all have significant information exchange requirements, not only with business partners, but also internally and with peer agencies. Whenever a number of applications or parties need to exchange information, agreed formats are required. But managing the agreed formats over time, what with multiple versions, multiple formats for similar information, and multiple applications consuming the same model and needing to manage change impact, it gets complicated.
That’s where this forum focused – how do you really manage the models and metadata over time, and how do you make them easy enough for developers to consume that they really will use them, rather than just build more point-to-point interfaces? Multiple versions of these modeled formats have to be managed over time, along with the mapping and transformation rules to the internal applications that produce or consume exchange messages.
Historically messages or even file-transfer were the dominant means of conveying these XML payloads, but in recent years, SOA has added another important context which benefits from rationalization of the model of “data in motion” through the communication infrastructure. As one attendee said, “SOA does not solve your data problems, it exposes them.” Of course, one can treat a message queue or ESB as a “tower of Babel” which conveys payloads between endpoints in a way that is semantically equivalent to point-to-point interfaces. But several of the information architects who spoke were able to articulate key benefits from rationalizing the information model to a canonical form:
- For large enterprises with many schemas under management, governance overhead and change management issues were significantly reduced by having a canonical model. This indirectly resulted in higher data quality, but most had found that data quality was not an argument that could be used to justify a canonical model “up front.”
- Most of the large enterprises also faced significant business change that demands much more rapid delivery of new products or services, in an increasingly integrated, straight-through manner. This requires integration of multiple, previously stove-piped systems, which the canonical model accelerates.
- Although developers were not among the early “boosters” of the idea, those organizations that had established a model, as well as the ability to quickly deliver the artifacts that developers need to easily work with it, found that developers came to take this capability for granted. They found that it really did accelerate the startup phase of their projects, by eliminating work they would have otherwise needed to do to obtain the information their applications require.
There Were Some Controversial Points
Some interesting points of controversy came up around the topic, reflecting the different perspectives in the room:
- One organization argued that canonical models can be applied to “data at rest” just as much as “data in motion,” although most were more focused on exchanges. This organization, an insurance company, had implemented IBM’s IAA, and so used its models for stored data as well.
- Some architects argued that it helps to have a “big stick” to get people to adopt a canonical model – i.e., the CIO’s mandate, or some similar backing – while others argued the effort needs to deliver such benefits to developers that it grows naturally at the grass roots. The difference probably reflected the differences in the political environment inside these organizations.
- One very sage senior architect pointed out that we’ve had canonical models for many years, for more than just data – also including models for processes, and more recently, for events. His point was that this group was brought together by a newer set of requirements that came from having this situation in the context of XML Schemas, which present certain modeling problems, such as being hierarchical in nature, whereas the abstract model has bidirectional relationships.
Still, Many Best Practices Emerged From The Attendees’ Experience
But there was much more agreement, than not. Several common observations or best practices emerged from the discussion:
- The canonical model is for interchanges, not endpoint application models. Notwithstanding the point made by the insurance company that implemented IAA, most organizations were focusing on exchanges, and found more success by limiting the scope of the model to just the most important exchanges at first, then working out over time from that starting point.
- The canonical model reduces overall complexity. It does this by adding one more “hop” or translation to the message path (compared to “point-to-point” semantic mapping between endpoints), so the cost of this extra hop may be too much for a very limited number of extreme performance-critical applications. Therefore it’s important to validate the architecture for these performance-critical applications, but otherwise make it the rule rather than the exception.
- A central group should manage mapping legacy/source systems into the canonical model. Part of the value to teams consuming the model is not having to worry about the complexities of accessing information from back-end data sources. Centralizing these concerns in a Center of Excellence or architecture group was, overall, the more economical thing to do.
- But don't centrally manage mappings to endpoints. Push responsibility for mapping out to the endpoint applications that will consume information off the “bus” (or information-access “layer,” in some cases). These newer applications are continuously changing and being extended to meet new business requirements, and they are in the best position to manage change and know what makes the most sense for them, economically.
- Applications that consume information from the bus should only take what they need. That way they are only exposed to changes in those elements. That means there are more versions of the message coming off the bus, but they are all subsets of a larger standard message – or more precisely, all different “projections” into XML Schema of a larger, single, logical model. The idea of the logical model is important to support the full range of relationships within the data that can exist, and not be constrained to modeling in hierarchies.
- The model should have a core that is standardized across all areas. Individual application domains can go beyond the core model with extensions (modeled as extensions in generated schemas, too) when they need something beyond the core model. Only expose those extensions to each relevant domain, minimizing the impact to other domains that never need to be exposed to that extension-data, or its changes.
- Domains that require such extensions should bear the cost of their creation and maintenance. This holds down the volume of these extensions to a manageable level. One large bank takes this approach, for example.
- Limit exposure to the canonical model by using adapters to isolate applications. This preserves the applications’ own interchange formats, converting to the canonical format in the bus but not requiring the application to entirely adopt that model.
So What About Tools?
Given that a vendor of a tool that addresses some of these issues (DigitalML) sponsored the meeting, it’s not surprising that the subject of tools came up several times. Those who were using IgniteXML had positive things to say about it, especially its unique level of support for a wide range of issues for both modelers and developers. One idea IgniteXML got particularly right is in providing tool support that makes it easy for developers to consume the model, given the critical path this plays in overall acceptance and success of canonical modeling initiatives.
Yet Forrester’s data shows that most information architects use more familiar tools for building their canonical information models (caution – this is a small sample size, so not necessarily indicative of the broader market, except in a very approximate way):
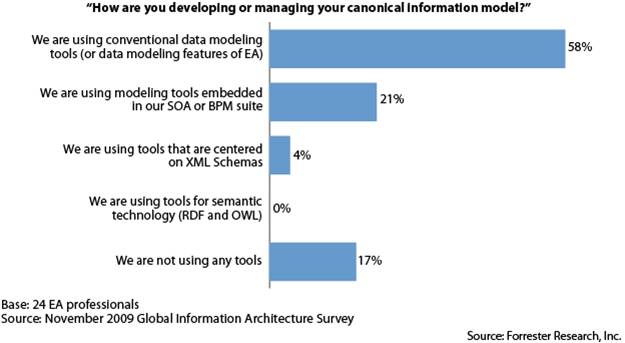
Notwithstanding this information, several attendees described their earlier efforts of managing a canonical model using conventional data modeling tools as having been only partly successful, with a lack of rich support for XML Schemas being one issue, and a lack of support for developers to consume models as XSDs being another. Another problem of the conventional tools approach was that it tended to put the EA group into a tightly-coupled workflow with developers that slowed down time-to-market for new applications that caused model impact – a death knell to accelerating adoption. Those that had moved to IgniteXML had found it much superior to those other tools, but were somewhat puzzled that as they looked around for alternatives that do the same thing, they couldn’t find any that were directly comparable. So clearly this is an immature tools category, which has not yet caught significant attention from the industry.
We did hear two other tools mentioned as not being so directly comparable, but still focused in the same general area of working with XML Schemas: Progress Software DataXchange Semantic Integrator (DXSI), and Liaison Contivo. Contivo was mentioned by one architect as a tool his firm had used in the past to try to implement its canonical modeling strategy (among other things), but that they had moved to IgniteXML and found it better suited to that requirement. Architects who mentioned DXSI did not make a direct comparison, but instead remarked that it seemed to be positioned somewhat differently than IgniteXML, and that it might be more complementary than competitive. We shouldn't read too much into these remarks, since these attendees were either current IgniteXML customers, or prospects, so don't represent a broad and general sample.
Forrester will be doing more research in this area, as clearly there are many questions we need to answer, such as what tools are really in this space and how they compare, as well as further investigation of best practices. Dave West and I will do that work. Please contact us if you have a case-study or a product we should evaluate.
Thanks,
Mike Gilpin
mgilpin@forrester.com