What’s Your Big Data Score?
If you think the term "Big Data" is wishy washy waste, then you are not alone. Many struggle to find a definition of Big Data that is anything more than awe-inspiring hugeness. But Big Data is real if you have an actionable definition that you can use to answer the question: "Does my organization have Big Data?" Proposed is a definition that takes into account both the measure of data and the activities performed with the data. Be sure to scroll down to calculate your Big Data Score.
Big Data Can Be Measured
Big Data exhibits extremity across one or many of these three alliterate measures:
- Volume. Metric prefixes rule the day when it comes to defining Big Data volume. In order of ascending magnitude: kilobyte, megabyte, gigabyte, terabyte, petabyte, exabyte, zettabyte, and yottabyte. A yottabyte is 1,000,000,000,000,000,000,000,000 bytes = 10 to the 24th power bytes. Wow! The first hard disk drive from IBM stored 3.75MB in 1956. That’s chump change compared to the 3TB Seagate harddrive I can buy at Amazon for $165.86. And, that’s just personal storage, IBM, Oracle, Teradata, and others have huge, fast storage capabilities for files and databases.
- Velocity. Big data can come fast. Imagine dealing with 5TB per second as Akamai does on its content delivery and acceleration network. Or, algorithmic trading engines that must detect trade buy/sell patterns in which complex event processing platforms such as Progress Apama have 100 microseconds to detect trades coming in at 5,000 orders per second. RFID, GPS, and many other data can arrive fast enough to require technologies such as SAP Hana and Rainstor to capture it fast enough.
- Variety. There are thirty flavors of Pop-Tarts. Flavors of data can be just as shocking because combinations of relational data, unstructured data such as text, images, video, and every other variation can cause complexity in storing, processing, and querying that data. NoSQL databases such as MongoDB and Apache Cassandra are key-value stores that can store unstructured data with ease. Distributed processing engines like Hadoop can be used to process variety and volume (but, not velocity). Distributed in-memory caching platforms like VMware vFabric GemFire can store a variety of objects and is fast to boot because of in-memory.
Volume, velocity, and variety are fine measures of Big Data, but they are open-ended. There is no specific volume, velocity, or variety of data that constitutes big. If a yottabyte is Big Data, then doesn’t that mean a petabyte is not? So, how do you know if your organization has Big Data?
The Big Data Theory of Relativity
Big Data is relative. One organization’s Big Data is another organization’s peanut. It all comes down to how well you can handle these three Big Data activities:
- Store. Can you store all the data, whether it is persistent or transient?
- Process. Can you cleanse, enrich, calculate, translate, or run algorithms, analytics, or otherwise against the data?
- Query. Can you search the data?
Calculate Your Big Data Score
For each combination of Big Data measures (volume, velocity, variety) and activities (store, process, query) in the table below enter a score:
- 5 = Handled perfectly or not required
- 3 = Handled ok but could be improved
- 1 = Handled poorly and frequently results in negative business impact
- 0 = Need exists but not handled.
Add up your scores in the points column and then sum at the bottom to get your Big Data score.
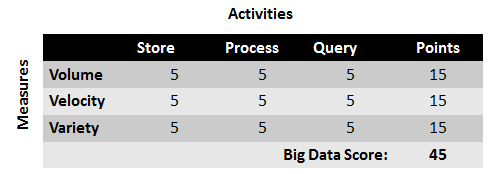
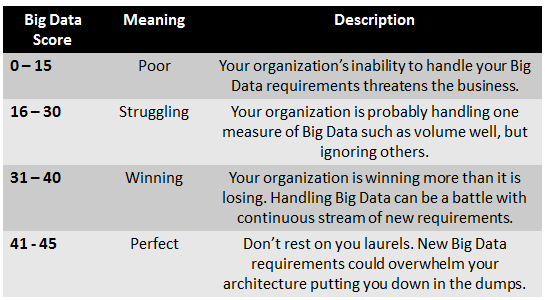
Once you have tallied your score, look in the table below to find out what it means.
I hope this helps and by all means, let me know how to improve this.
Mike Gualtieri, Principal Analyst, Forrester Research
Categories
