A Week After Hurricane Sandy: How Did Our Business Technology Resiliency Plans Fare?
A little more than a week after Hurricane Sandy barreled through the Eastern seaboard, I wanted to take a moment and share some of my thoughts on business technology resiliency* and how we fared during this significant weather event. While there are still over a million people without electricity and significant recovery efforts underway, I'm overall impressed with the level of resiliency and preparedness many organizations exhibited during (and since) Sandy. I stress resiliency over recovery here because I believe that is the future of disaster recovery and business continuity. Our official definition is: “The ability for business technology to absorb the impact of any unexpected occurrence without disrupting business operations.”
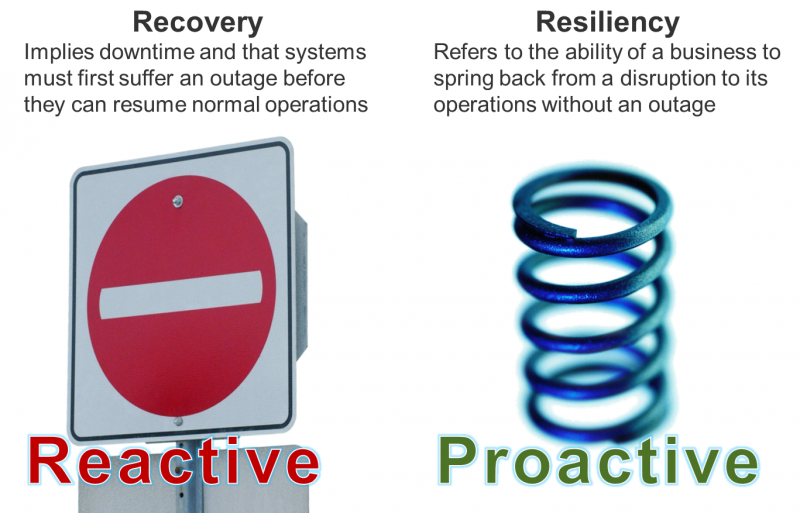
While almost all companies with a presence in Sandy’s path suffered some level of disruption, most were able to carry on operations. Some examples of the key tenets of a mature business technology resiliency program include:
- Proactive. During this event more than any other, I saw organizations being proactive, some deciding to close offices as of the Friday before the storm to prevent potential miscommunications with employees over the weekend. Some companies even invoked DR plans to failover data centers before the hurricane hit.
- Tested. Firms are also realizing the value of exercises and drills — our own chief business technology officer at Forrester, Steve Peltzman, wisely elected to run a test of our own emergency notification system on Friday; the system was then needed on Saturday to notify employees that several offices would be closed. Another organization I work with ran a workforce continuity drill just a week before the storm, sending employees home to work remotely to prepare for an event like Sandy.
- Effectively communicated. Communications were also greatly improved, as my colleague Stephanie Balaouras noted in a recent blog. Utilities and government agencies tweeted and set up tracking and communication pages. Data center service providers blogged and tweeted blow-by-blow developments of data centers in impacted zones.
The landscape has not been completely rosy, however; there are several examples of shortcomings during the storm:
- Preventable IT failures. There have been several large-scale IT disasters, many of which could have been prevented with proper planning and testing. It’s interesting to see that even during a massive disaster like Hurricane Sandy, it’s the little things that take down data center facilities: UPS failures, network failures, fuel shortages, etc., all the cascading events that occur after the hurricane.
- Work from home strategies. Like I noted in an earlier post, 81% of companies use work from home strategies for workforce continuity during disasters. But during Hurricane Sandy, many organizations who counted on employees working from home for workforce recovery found their strategies fall flat when power, network, and cell coverage failed across 10 states. However, there were reports of some organizations getting hotel rooms for displaced employees and their families
- Hospital preparedness. Across New Jersey and New York, four hospitals were forced to shut down and evacuate and relocate patients after generators failed. This has prompted a re-evaluation as to when hospitals should be preemptively evacuated. On the IT front, other hospitals in the region were able to continuing accepting patients, but lost IT systems. Some were able to successfully revert to paper records, others could not.
We are working on a more formal analysis of the lessons learned from Hurricane Sandy to publish on the Forrester website, but in the interim, these are my initial thoughts and reactions. We've also made our business technology resiliency playbook free of charge through the end of November. I encourage you to check out the research here (site registration required).
*Forrester defines business technology resiliency as a hybrid discipline combining aspects of disaster recovery, business continuity, backup, high availability, and information security that focuses on maintaining highly available operations, proactively taking steps to improve uptime, and responding to all likely causes of outages.