Symcat Fights “Cyberchondria” With Health Data

How many of you suffer from at least mild “cyberchondria"? Do you run to the computer to Google your latest ailments? Are you often convinced that the headache you have is the first sign of some terminal illness you’ve been reading about?
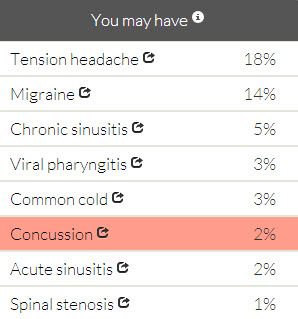 Well, Symcat takes a new approach to Internet-assisted self-diagnosis. It provides not only the symptoms but the probability of getting the disease, using CDC data to rank results by the likelihood of the different conditions. It then allows users to further filter results by typing in information such as their gender, the duration of their symptoms and medical history. No, that headache you’ve had all week is likely not spinal stenosis or even viral pharyngitis. But if you’ve had a fall or a blow to the head you might want to consider a concussion.
Well, Symcat takes a new approach to Internet-assisted self-diagnosis. It provides not only the symptoms but the probability of getting the disease, using CDC data to rank results by the likelihood of the different conditions. It then allows users to further filter results by typing in information such as their gender, the duration of their symptoms and medical history. No, that headache you’ve had all week is likely not spinal stenosis or even viral pharyngitis. But if you’ve had a fall or a blow to the head you might want to consider a concussion.
As Symcat puts it, they “use data to help you feel better.” Never underestimate the palliative effects of peace of mind.
I had the chance to ask Craig Monsen, MD, co-founder and CEO of Symcat, a few questions about how they got their start with the business and their innovation with open data.
What was the genesis of Symcat? Can you describe the "ah-ha" moment of determining the need for Symcat?
Symcat has evolved a fair bit since its original conception. David, one of the other founders, and I first conceived of it during our time in medical school at Johns Hopkins. We (painfully) memorized commonly-observed associations in medicine: symptoms to diagnoses, diagnoses to tests, diagnoses to medications, medications to side effects. The ubiquity of computers and their comparative advantage in memory-based tasks invited our reflection about how we could ease our own cognitive load as students.
Thus, we originally developed Symcat as a tool for medical trainees like ourselves. We built most of the prototype during our rotation in the Emergency Room to help inform us about what conditions patients were likely to have. It was the usual typically-overcrowded ER, the gateway to medical care for so many. There, we learned that patients had an even greater need for this information. It seemed that, actually, there were relatively few emergencies. Many people were arriving because they could not reach their primary care doctor or they did not have one or they genuinely thought that they were experiencing an emergency and did not have the information to know for sure. We knew that there needed to be an alternative: a data-driven, personalized resource that could act as a new, convenient, and cost-effective gateway.
We’ve discovered along the way that this need permeates most of health care. The health care system is complex, a black box for doctors and an even blacker box for patients. Patients get only what they can find on the Internet to supplement brief conversations with their providers. Yet, with 135 specialists, thousands of procedures, medications, and diseases, you need an MD just to know which address to go to for your health problem. And the address is probably wrong.
For these reasons, recent legislation is moving us towards a market-based solution, inviting transparency through open data initiatives and consumerism though, well, making consumers pay more. We’re stepping in to help consumers make sense of health data, most of all their own, and enable them to make smarter health care choices.
Who is your target audience?
Although we started with a focus on medical providers and trainees, Symcat is for everyone. Many of our users are doctors like us, but we prefer to keep it openly accessible. We aim to create a resource that patients and their physicians can discuss together.
How do you identify the appropriate and available data to power the service?
We regularly add new data to Symcat. One of the ways I encounter appropriate data is by staying up to date on the medical literature. No one has designed their dataset with Symcat in mind, so we often need to co-opt datasets originally intended for public health analysis, for instance.
The US government in general and the Department of Health and Human Services (HHS) in particular have been working hard to publicize the opening of additional datasets through healthdata.gov. I also check on that regularly.
How did you actually find the data? Word-of-mouth? A data catalog? Promotion by the source agency?
All of the above. I can’t easily generalize on this, but Google is a surprisingly effective resource.
Did you participate in an app development contest or hackathon? Who was the sponsor? Which data was made available?
We participated in two challenges early on in our development. The first was the Robert Wood Johnson Foundation Aligning Forces 4 Quality Challenge (AF4Q). They made available outpatient provider quality data from their AF4Q sites. The second challenge was the Cigna Innovation Health Challenge. They made available an API for managing medications. [Editorial note: Symcat took first prize at both AF4Q and Cigna.]
How do you consume the data? Download? API-enabled feed?
The AF4Q were all downloads, with as many formats as there were sites (13, I believe). Cigna offered an API.
Are the data sources sustainable in the long-run? Are there guarantees of sustainability?
I think the Robert Wood Johnson Foundation struggled with this very question. The AF4Q initiative was a 5-year, multi-million dollar initiative that recently concluded. The sites that have been developing the data are looking for new revenue streams for the data to keep working on it. I am not sure if they are going to find payers, but we will see.
In general, data sources may come and go, but we have the infrastructure to swap them out or incorporate new ones if they become stale.
Is there a licensing requirement? Attribution?
Generally, data sources require attribution and a licensing agreement. These vary, but are usually pretty permissive.
What is the business model? Fee-based? Revenue-sharing?
I’ve generally seen annual licenses for using datasets when they require a fee. There are several lifetime licenses as well, but they update the datasets annually making them effectively annual licenses.
Is there a process for feedback on data quality or timeliness?
Datasets are pretty much without exception provided “as is.”
And what about your business model?
We are working with hospital networks to enable the accountable care and patient-centered medical home models. This means linking our rather generalized datasets to match the particular structure of a health network both to improve patient health and offer convenience to accessing the services of the network.
I am also very excited about our B2C freemium model whereby 80% of the functionality of Symcat is offered free of charge, with options to purchase premium features and services, some of which may be offered through our provider partners (e.g. through telehealth services).
What is your strategy for growth/expansion? Other countries? Other services? Other data sources?
For the foreseeable future, we will grow through offering additional data-driven services. In addition to symptom-based routing to medical facilities, we are releasing self-care medication options, additional diagnostic and treatment options for self-referral to labs or specialists (as clinically indicated), and pricing information to inform those decisions. These services rely heavily on incorporating new datasets. At the moment, we are working with roughly 40 datasets representing well over 100 million patient visits.
Have you raised funding? How much? From whom or what type of sources?
We have raised funding, but I am unable to disclose from whom or how much. I can say that we have won $115k in prizes from the Robert Wood Johnson Foundation and Cigna.
How many employees do you have?
We currently have five employees and are hiring additional web developers and data scientists.
And, there’s the proof that open data enables innovation, attracts investment (although we don’t know how much in this case), creates jobs and generates economic and social value. I, for one, see enormous value in the peace of mind Symcat offers. Thanks guys!
Craig Monsen, MD, is the co-founder and CEO of Symcat, a data-driven health information resource for patients. He writes occasionally for blog.symcat.com.