RAG Is All The Rage — And The Machine Is Getting More Complex
In our previous blog post on retrieval-augmented generation (RAG), we explained the motivation for implementing a RAG architecture and presented a very basic example architecture for retrieving enterprise knowledge. But the solution doesn’t stop there; in this blog post, we’ll describe advanced RAG architectures for enterprise knowledge applications.
In the previous post, we showed how a RAG-powered application could handle some simple HR questions. Using that simple architecture, if a user were to prompt the system with a more complex question (e.g., “How many sick days do I have per year?”), the system will only be able to respond with a general answer applicable to any employee at the company. But with one small tweak, we can start generating responses tailored to the individual user.
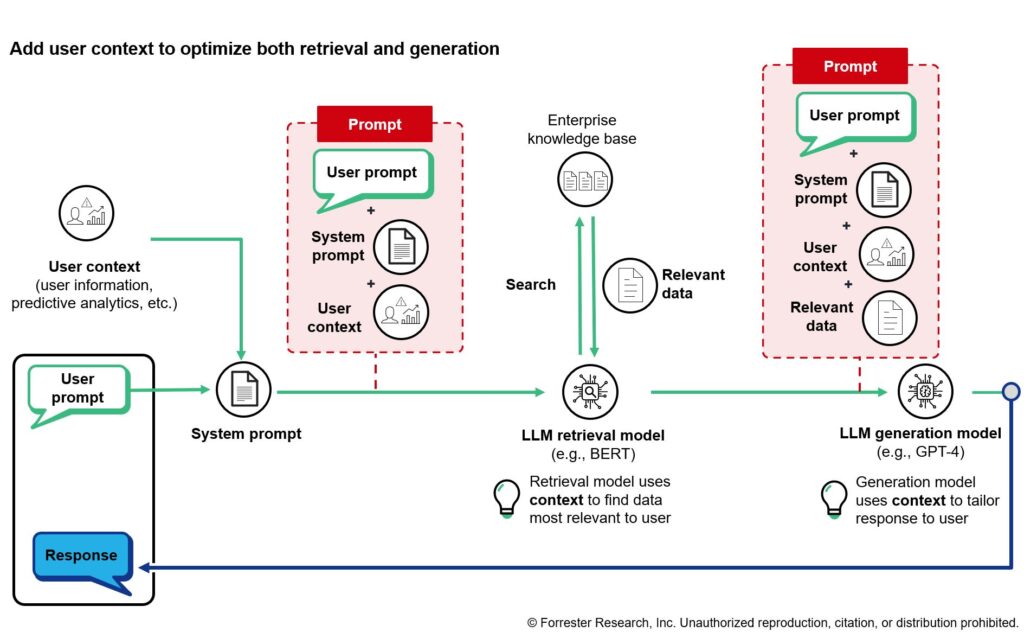
User Context Customizes Retrieval And Generation To The User
By furnishing an AI application with user context, we ensure that the retrieval model finds the information relevant to the user. For example, for a help desk application for answering questions about sick days, the critical context is the user’s length of employment. The retrieval model can locate the company policy on sick days, and the generation model can use the user context (including length of tenure) and company policy to work out how many days are available to the employee; together, they can then craft a response.
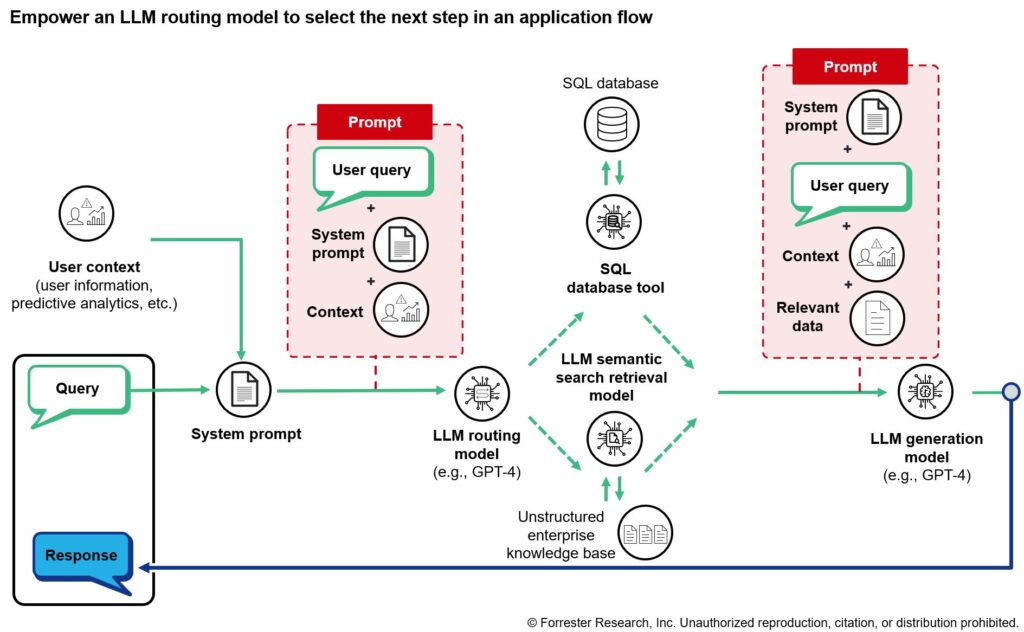
LLM Routing Models Determine Application Flows
The example above works great for an application that needs to leverage a single source of data (e.g., unstructured how-to pages). But we must adjust the application if we want it to be flexible enough to respond to a wider range of prompts. Suppose an employee also asks, “How many sick days do I have left this year?” To answer this, the application will have to query the HR system’s structured database, but we’ll want the application to continue to have access to unstructured enterprise knowledge in case users ask general policy questions.
To make this possible, we’ll use a large language model (LLM) as a reasoning engine to determine whether the next step in the application flow should be structured HR data retrieval or unstructured enterprise knowledge retrieval (shown in the diagram below as a routing model). For a query about sick days remaining, the LLM determines that the best tool would be the SQL database query tool that retrieves information from an HR database housing employee information including sick days.
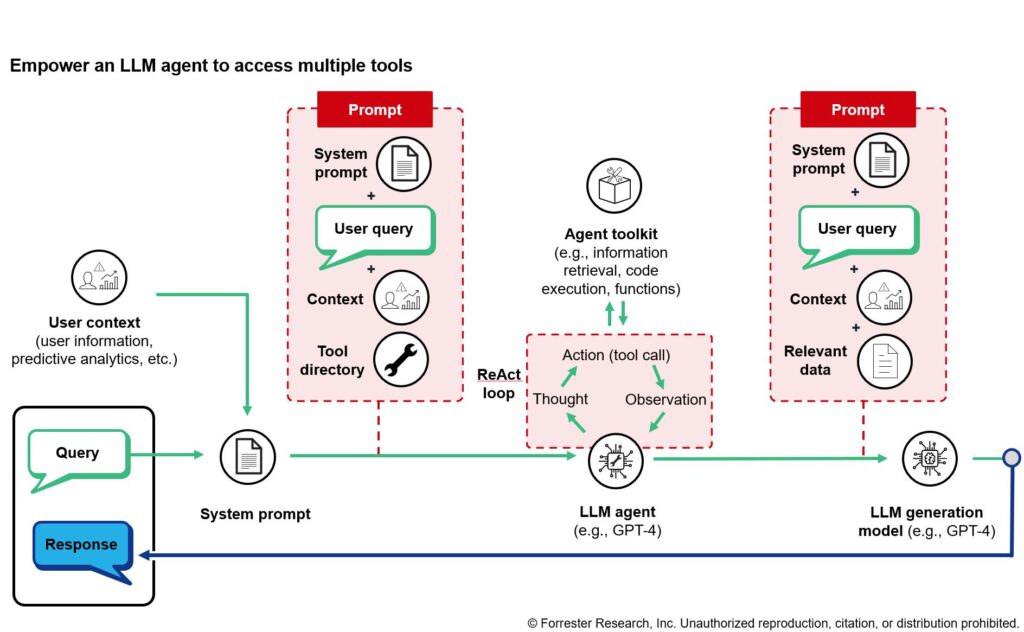
Complex Reasoning With An Agent Framework And Tools
For more complex queries, after an initial retrieval step and reasoning step, it may be necessary to retrieve further information. For example, an employee wants to know how many days of paid leave they’ll be able to take off when their child is born. Answering this question requires pulling together multiple strands of disparate information: how long the employee has been with the company, the company’s parental leave policy, how many vacation days the employee has accrued, and where they are employed. Basic information like length of employment and location of employment may already be in the user context, so let’s suppose the system only needs to look up the company’s parental leave policy and then look up how many vacation days the employee has accrued.
This type of multistep reasoning, where new information is needed at each step, can be accomplished using an LLM agent framework. An LLM agent is given a prompt that includes a directory of tools it can use (e.g., structured data retrieval, unstructured data retrieval, code execution). As the LLM agent works through the solution to a query, not only can it select the tool it deems most appropriate, but it can also use new information to adjust its plan for solving a query. One common paradigm for this is called ReAct, wherein the LLM agent is prompted to think about how to solve a problem, then carry out an action (i.e., use a tool), then provide an observation of what it learned from the action, then return back to the thinking step (and continue along this loop until the query is solved).
Bringing RAG And Generative AI Applications To Your Company
Architectures, best practices, development methodologies, and testing strategies are still rapidly evolving in the AI application space — and it can be truly overwhelming to make decisions as a technology leader. If you have questions or challenges that you’re facing in building and deploying generative AI applications, reach out to schedule an inquiry or guidance session.
Related Research
Forrester clients can access the following reports related to building RAG applications for enterprise knowledge:
- The Architect’s Guide To Generative AI
- The AI Foundation Models For Language Landscape, Q2 2024
- The Forrester Wave™: AI Foundation Models For Language, Q2 2024
- The AI/ML Platforms Landscape, Q1 2024
- Build Efficient And Robust GenAI Apps With Prompt Engineering And Advanced LLM App Architectures
- Generative AI Glossary: Concepts, Techniques, And Technologies
