Inspire Trust With Robust, Well-Tested AI-Infused Applications
Software takes part in almost everything we do, and yes, we do trust that it works. Yes, sometimes it fails and it drives us nuts, but in most cases, it does what we expect it to do. How have we learned to trust that software works? Through positive experiences with software that meets our expectations. And well-tested software avoids destroying customer experience, since customers never see the bugs — they get identified and fixed earlier in the development process.
Similarly, we are also learning to trust AI, which is increasingly being infused into software and apps that we use every day (although not yet at the scale of traditional software). But there are also plenty of examples of bad experiences with AI that compromise ethics, accountability, and inclusiveness and thus erode trust. For example, as we describe in No Testing Means No Trust In AI: Part 1, Compas is a machine-learning- (ML) and AI-infused application (AIIA) that judges in 12 US states use to help decide whether to allow defendants out on bail before trial and to help decide on the length of prison sentences. Researchers found that Compas often predicted Black defendants to be at a higher risk of recidivism than they actually were, while it often underestimated the risk that white defendants would reoffend.
Losing trust in AIIAs is a high risk for AI-based innovation. The additional expectation we humans have of AI-infused applications is that, besides just working, we expect intelligent behavior: AIIAs must speak, listen, see, and understand. Forrester’s Data And Analytics Survey, 2022, shows that 73% of enterprises are implementing or have implemented AI/ML/deep learning in 2022, up from 67% in 2021, and testing those AI-infused applications thus becomes even more critical.
 The consequences of not testing AIIAs enough loom even larger for applications in areas that impact life and safety (think self-driving cars and automated factories), cybersecurity, or strategic decision support. And as AI improves and we gradually reduce human intervention, testing AIIAs becomes even more critical.
The consequences of not testing AIIAs enough loom even larger for applications in areas that impact life and safety (think self-driving cars and automated factories), cybersecurity, or strategic decision support. And as AI improves and we gradually reduce human intervention, testing AIIAs becomes even more critical.
Most indications from our own research and other sources show that more and more IT leaders are either thinking of using AI in testing or of testing their AI. So we expect explosive growth in AIIA testing. Here are some of the most common questions we get from clients around the topic of AI testing:
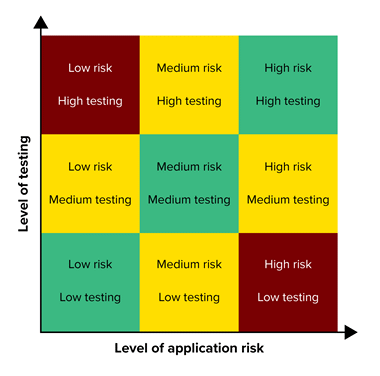
1) How do I balance the risk of not testing enough or testing too much for AIIAs?
2) How I do know if I’m testing AI sufficiently?
3) Testing AIIAs takes a village. What roles should be involved?
4) Which of the existing testing practices and skills can I use, and which new ones do I need?
5) Is testing equal for all types of AI involved?
6) What about automation of testing AIIAs?
7) How does that automation integrate into MLOps (DevOps for AI)?
If you are among the 73% adopting AI to make your enterprise smarter, faster, and more creative, watch this video to get answers to your most common questions.
Related Forrester Content
